
Кто круче Шварценеггер или Сталлоне GCC или LLVM? Этот вопрос уже давно мучает многих людей на форумах. На эту тему можно много рассуждать, рассматривая с разных сторон. Но существуют относительно объективные критерии оценки.
Нашёл я тут на днях очень интересный замер - сравнение gcc и llvm на SPEC 2000. Если вкратце, то SPEC - промышленный бенчмарк, в том числе для замеров качества оптимизаций компилятора. Если хочется сравнить 2 компилятора, то использовать нужно именно этот набор.
Сразу оговорюсь, что конкретной информации по этим замерам автором предоставлено довольно мало, поэтому все рассуждения будут примерными и с реальностью пересекаться не обязаны.
Будем рассматривать только x86_64 версию сравнения. Посмотрим какие режимы работы компиляторов сравнивались:
К сожалению конкретных ключей сборки не указано, поэтому точно проанализировать результаты невозможно. Режимы сборки -O1,-O2,-O3 известны большинству людей. А вот об остальных расскажу чуть подробнее.
Для llvm:
Время компиляции:
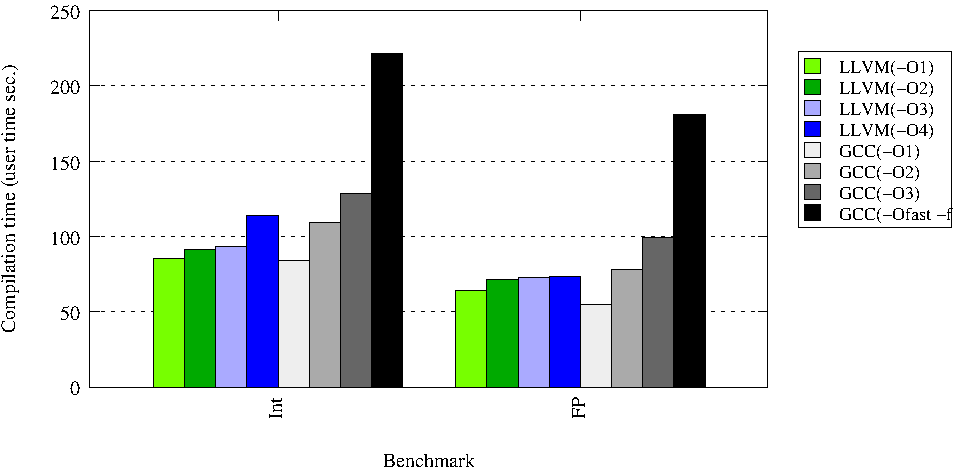 Тут Int означает сборку целочисленных задач, FP - сборка задач с плавающей запятой. Их разделяют т.к. это два разных класса задач, которые по-разному исполняются на процессоре и к которым могут применяться разные оптимизации.
Тут Int означает сборку целочисленных задач, FP - сборка задач с плавающей запятой. Их разделяют т.к. это два разных класса задач, которые по-разному исполняются на процессоре и к которым могут применяться разные оптимизации.
Из графиков видно, что везде кроме уровня -O1 llvm показывает более быстрое время компиляции. Особенно это заметно при межмодульных оптимизациях, что особенно важно, т.к. это одно из наиболее актуальных направлений развития компиляторов.
Часто приходится слышать мнение, что скорость llvm обусловлена малым количеством оптимизаций и он генерирует более медленный код. А скорость исполнения гораздо важнее скорости компиляции. Если компиляция длится конечное время, конечно. А мне известны случаи когда в промышленных компиляторах это условие не выполнялось. Ну почти.
Чем рассуждать просто посмотрим результаты скорости исполнения.
Целочисленные задачи:
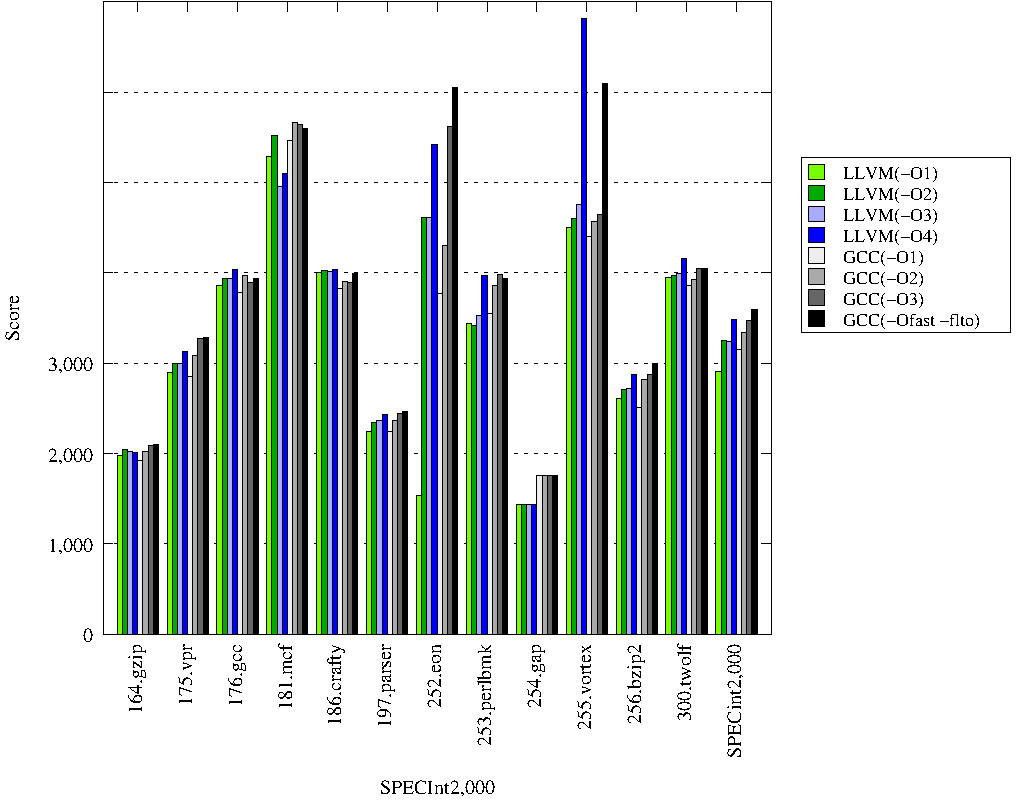 Очень интересный результат, т.к. llvm в среднем лучше оптимизирует на -O2 чем на -O3. При этом в среднем он значительно проигрывает gcc в аналогичных режимах. Хотя скачок на 255.vortex в режиме -O4 выглядит забавно. Также автор сравнения указал, что llvm ни с одним уровнем оптимизации не собирает задачу 254.gap.
Очень интересный результат, т.к. llvm в среднем лучше оптимизирует на -O2 чем на -O3. При этом в среднем он значительно проигрывает gcc в аналогичных режимах. Хотя скачок на 255.vortex в режиме -O4 выглядит забавно. Также автор сравнения указал, что llvm ни с одним уровнем оптимизации не собирает задачу 254.gap.
Плавучка:
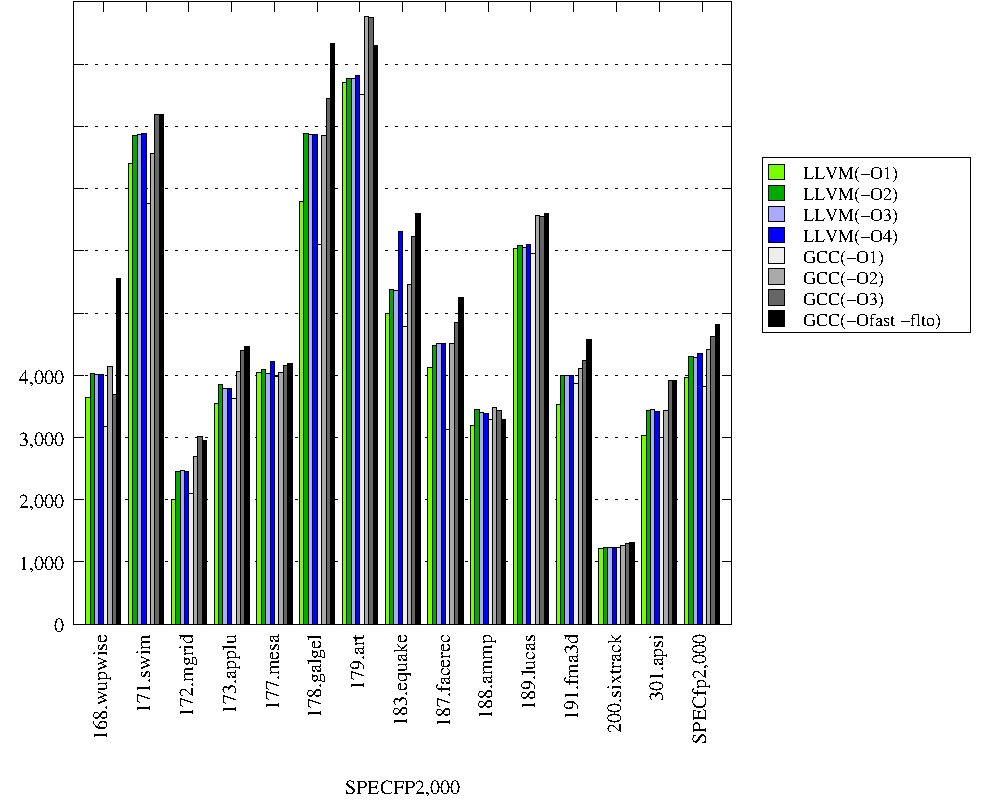
Тут всё совсем грустно и llvm разгромлен полностью. Режим llvm -O4 оказался хуже gcc'шного -O2. И опять llvm с опцией -O2 победил себя же с опцией -O3.
Какой отсюда можно сделать вывод? Пока что нет особых причин использовать llvm, только если проект не собирается на ключе -O1. Но если посмотреть на сравнения от предыдущих годов, в которых llvm или не собирал SPEC'и на -O3 вообще, или не имел межмодульных оптимизаций, тенденция не может не радовать.
PS. Шварцнегер круче ;)
Нашёл я тут на днях очень интересный замер - сравнение gcc и llvm на SPEC 2000. Если вкратце, то SPEC - промышленный бенчмарк, в том числе для замеров качества оптимизаций компилятора. Если хочется сравнить 2 компилятора, то использовать нужно именно этот набор.
Сразу оговорюсь, что конкретной информации по этим замерам автором предоставлено довольно мало, поэтому все рассуждения будут примерными и с реальностью пересекаться не обязаны.
Будем рассматривать только x86_64 версию сравнения. Посмотрим какие режимы работы компиляторов сравнивались:
| LLVM-3.2 | -O1 -mtune=corei7 | -O2 -mtune=corei7 | -O3 -mtune=corei7 | -O4 -mtune=corei7 |
| GCC-4.8 | -O1 -mtune=corei7 | -O2 -mtune=corei7 | -O3 -mtune=corei7 | -Ofast -fno-fast-math -flto -fwhole-program -mtune=corei7 |
Для llvm:
-O4 включает оптимизацию времени связывания; в объектных файлах хранится байткод llvm и во время связывания проводится оптимизация в всей программы.Для gcc:
-Ofast пренебрегает строгими стандартами компиляции. -Ofast включает все оптимизации -O3. Она также включает оптимизации, которые некорректны для компиляции, совместимой со стандартом. Она включает -ffast-math и специфичные для Fortran'а -fno-protect-parens и -fstack-arraysНо при этом взведена опция -fno-fast-math, есть подозрение, что из-за её отсутствия ломались SPEC'и.
-flto[=n] Эта опция запускает стандартные оптимизации времени связывания. Будучи взведённой при компиляции исходного кода, она генерирует GIMPLE (одно из внутренних представлений GCC) и записывает его в специальные секции объектного ELF файла. Когда объектные файлы связываются вместе, все тела функций из этих секций ELF'ов обрабатываются так как если бы они были частью данного модуля.
-fwhole-program подразумевает, что текущая единица компиляции представляет из себя полностью компилируемую программу. Все public функции и переменные кроме "main" и тех, что помечены атрибутом "externally_visible" становятся статическими и в результате оптимизируются более агрессивно межпроцедурными оптимизациями.Ну, т.е. четвёртый режим обоих компиляторов - просто включённые межмодульные оптимизации. А теперь перейдём к результатам. Точнее к тому что можно увидеть на иллюстрациях.
Время компиляции:
Из графиков видно, что везде кроме уровня -O1 llvm показывает более быстрое время компиляции. Особенно это заметно при межмодульных оптимизациях, что особенно важно, т.к. это одно из наиболее актуальных направлений развития компиляторов.
Часто приходится слышать мнение, что скорость llvm обусловлена малым количеством оптимизаций и он генерирует более медленный код. А скорость исполнения гораздо важнее скорости компиляции. Если компиляция длится конечное время, конечно. А мне известны случаи когда в промышленных компиляторах это условие не выполнялось. Ну почти.
Чем рассуждать просто посмотрим результаты скорости исполнения.
Целочисленные задачи:
Плавучка:
Тут всё совсем грустно и llvm разгромлен полностью. Режим llvm -O4 оказался хуже gcc'шного -O2. И опять llvm с опцией -O2 победил себя же с опцией -O3.
Какой отсюда можно сделать вывод? Пока что нет особых причин использовать llvm, только если проект не собирается на ключе -O1. Но если посмотреть на сравнения от предыдущих годов, в которых llvm или не собирал SPEC'и на -O3 вообще, или не имел межмодульных оптимизаций, тенденция не может не радовать.
PS. Шварцнегер круче ;)
Комментариев нет:
Отправить комментарий
Примечание. Отправлять комментарии могут только участники этого блога.