
Я уже писал про сравнение gcc и llvm в 2013 году, и вот недавно вышло сравнение свежих версий. Сравнение претерпело некоторые изменения, и разумеется, хотелось бы об этом написать.
Итак, в этом году сравниваем gcc-4.9 и llvm-3.4. При этом добавлены результаты для gcc-4.8 и llvm-3.3. Бенчмарк стандартный - SPEC2000. Интересно, что автор делал замеры только на x86_64 и ARM, т.е. x86 разрядности 32 считает не интересной (т.к. производительность программ для 64 битов выше). Для ARM замеры производились впервые. Не производились замеры fortran, и как следствие не тестировались плавающие вычисления т.к. у llvm нет фронтенда для фортрана, а использовать dragonegg слишком сложно.
А теперь, собственно замеры.
Скорость компиляции:

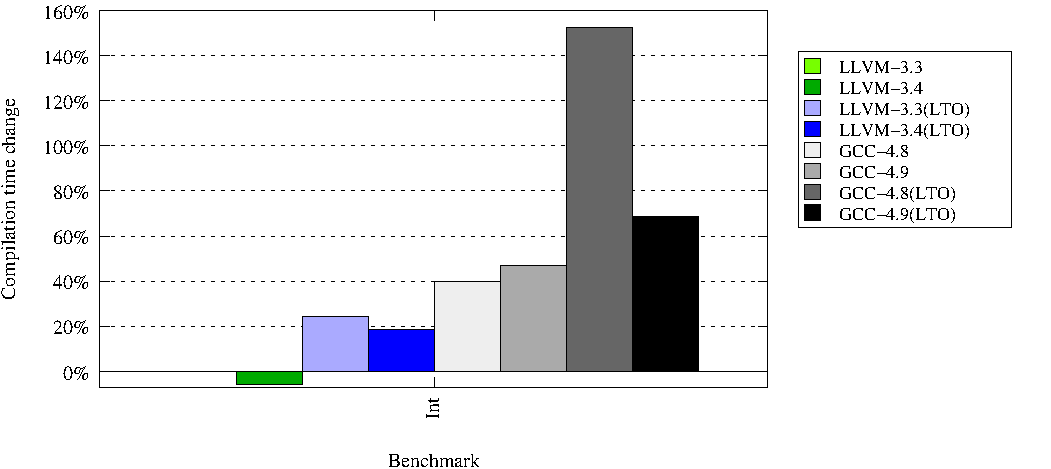
Размер сгенерённого кода пропущу, т.к. лично мне не особо интересно. Но он есть в оригинальном исследовании.
Самое интересное. Производительность:
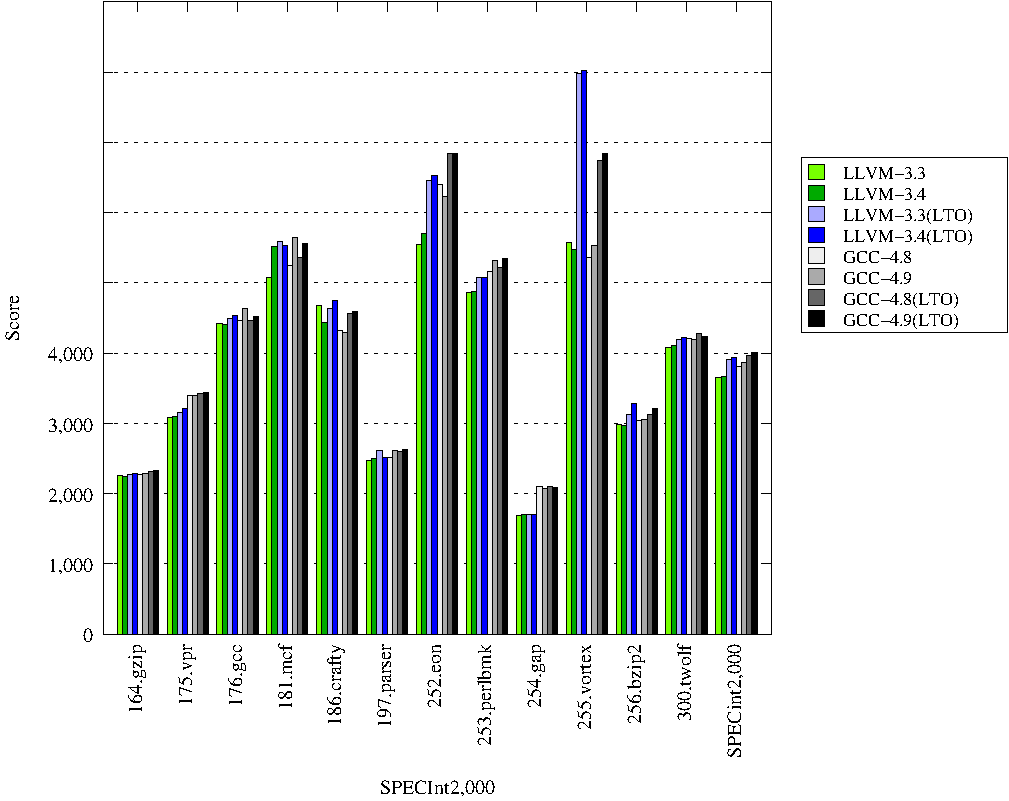
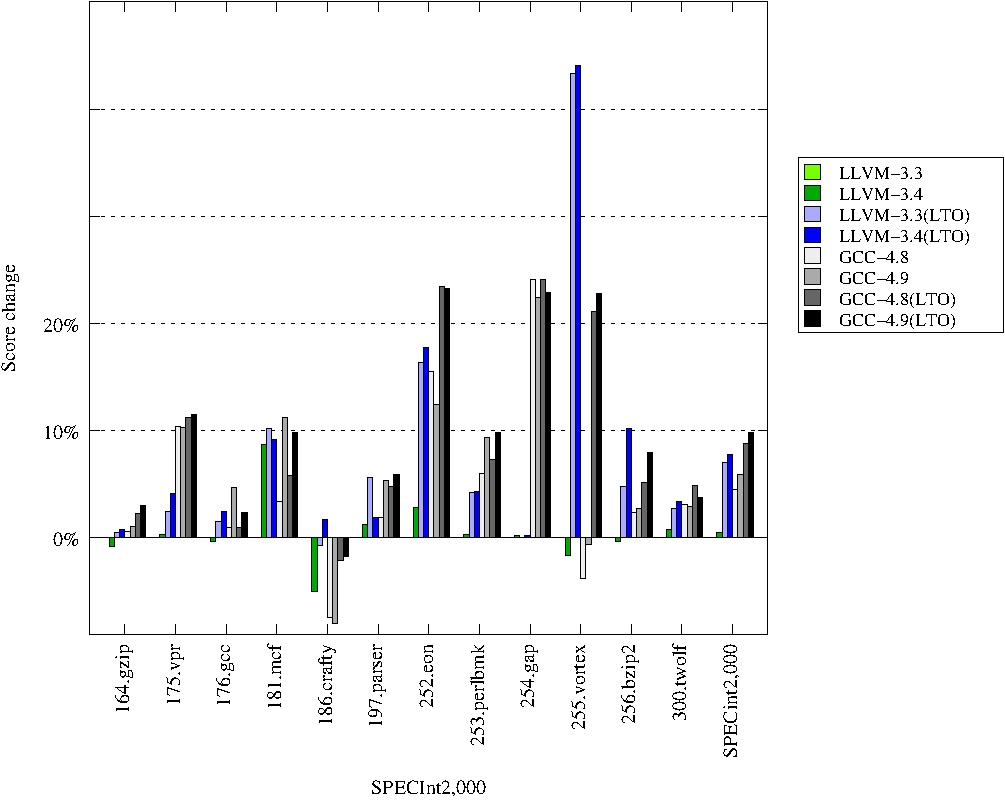
Исследования про ARM тоже публиковать не буду, их можно найти в оригинальном исследовании.
Теперь к выводам, сделанным автором исследования:
Итак, в этом году сравниваем gcc-4.9 и llvm-3.4. При этом добавлены результаты для gcc-4.8 и llvm-3.3. Бенчмарк стандартный - SPEC2000. Интересно, что автор делал замеры только на x86_64 и ARM, т.е. x86 разрядности 32 считает не интересной (т.к. производительность программ для 64 битов выше). Для ARM замеры производились впервые. Не производились замеры fortran, и как следствие не тестировались плавающие вычисления т.к. у llvm нет фронтенда для фортрана, а использовать dragonegg слишком сложно.
А теперь, собственно замеры.
Скорость компиляции:
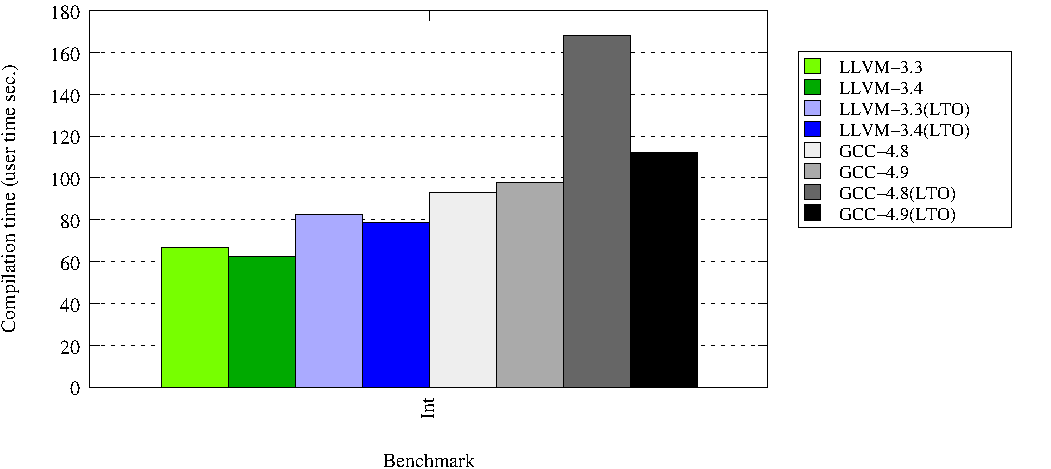
Размер сгенерённого кода пропущу, т.к. лично мне не особо интересно. Но он есть в оригинальном исследовании.
Самое интересное. Производительность:
Исследования про ARM тоже публиковать не буду, их можно найти в оригинальном исследовании.
Теперь к выводам, сделанным автором исследования:
- GCC из поколения в поколение показывает устойчивое улучшение производительности на x86-64. Производительность LLVM почти не поменялась.
- LLVM-3.4 улучшает скорость компиляции в то время как GCC-3.9 требуется больше времени для лучшей кодогенерации при выключенном LTO. С другой стороны скорость компиляции в режиме LTO была значительно увеличена в GCC-4.9. И это важное достижение.
- Разница между одними поколениями LLVM и GCC в целочисленных SPEC'ах на x86-64 на данный момент составляет 6% и 2% соответственно без LTO и с ним (для точных цифр можно посмотреть в таблицы). Этот разрыв меньше чем в моём сравнении 2013 года, когда он составлял 8% и 3.5%. Я думаю, главной причиной является прогресс процессоров Intel. В 2013 году я использовал процессор, который был старше на 2 поколения (Sandy Bridge). Процессоры Intel стали лучше исполнять неоптимизированный код, другими словами они стали менее чувствительны к некоторым оптимизациям.
- Для ARM GCC генерирует целочисленный код примерно на 10% лучше. Я верю, что GCC покажет себя лучше и на большинстве других, отличных от x86/x86-64 платформах. По крайней мере я видел схожие результаты на PPC.
- Я думаю, что сообществу GCC следует уделять больше внимания улучшению качества кода для x86-64, т.к. производительность LLVM уже действительно близка к GCC.
- Для улучшения производительности GCC нам нужны анализы, в которых другие компиляторы (LLVM или Intel ocmpiler) генерируют лучший код. К сожалению это работа на полную ставку для более чем одного человека, знакомого с основами компиляторостроения. Но если кому-нибудь интересно, я бы предложил проанализировать 186.crafty или 255.vortex в режиме LTO, где LLVM работает гораздо лучше чем GCC.
- У меня хватило немного времени для анализа сгенрированного кода и поиска разницы в генерации. У меня сложилось впечатление, что у LLVM получше с разрывом зависимостей, с другой стороны GCC лучше справляется с удалением мёртвых записей. Другое отличае в том, что LLVM систематически использует регистры SSE для перемещения структур в памяти. GCC использует общие регистры для этого. Я затрудняюсь сказать какой способ лучше для современного процессора без дополнительных исследований, но код LLVM обычно получается меньше т.к. регистры SEE шире. Я проверил компиляторы Intel, он также использует регистры общего назначения для этих целей.
Комментариев нет:
Отправить комментарий
Примечание. Отправлять комментарии могут только участники этого блога.